
Um artigo recente de alguns dos cientistas mais proeminentes em inteligência artificial (IA) imediatamente chamou a atenção da comunidade científica. Nele, os cientistas discutem a ideia de que já possuímos a principal técnica para produzir uma inteligência artificial geral (IAG). Vamos analisar alguns pontos importantes do artigo e procurar entender o motivo de tamanha empolgação.
O artigo, disponível aqui, é intitulado “Recompensa é Suficiente” (original: Reward is Enough) e foi publicado por quatro autores, entre eles estão: David Silver, líder da equipe de pesquisa em Aprendizado por Reforço (Reinforcement Learning ou RL) da DeepMind; e Richard S. Sutton, professor na Universidade de Alberta e também pesquisador na DeepMind.
Silver esteve à frente da equipe que desenvolveu o AlphaGo, IA famosa por ter sido a primeira a derrotar um jogador profissional de Go. Enquanto Sutton é considerado um dos fundadores da área de Aprendizado por Reforço e autor do livro mais famoso do mundo sobre o assunto, disponibilizado gratuitamente aqui. Há disponível no YouTube uma apresentação dele (em inglês) sobre o artigo que vamos discutir aqui.
A DeepMind é uma das empresas, ao lado da OpenAI, que vem liderando a pesquisa mundial em IA. Portanto, por mais presunçoso que pareça o artigo, devemos prestar atenção nele.
Aprendizado por Reforço e a recompensa
Para entender a hipótese e os argumentos levantados no artigo precisamos entender um pouco sobre esse tal Aprendizado por Reforço e do que se trata a recompensa.
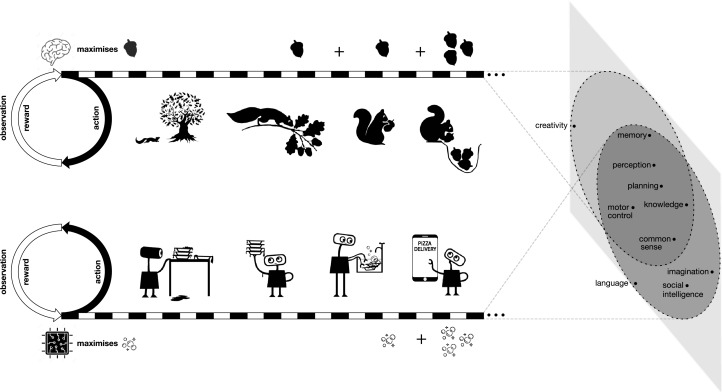
RL (Reinforcement Learning) é uma área de IA que estuda técnicas que visam treinar um agente (a inteligência artificial) que interage com um ambiente a aprender a realizar alguma tarefa. Entre os diversos mecanismos possíveis, todos têm em comum a característica de informar ao agente como seu desempenho está indo. Essa informação, que é uma medida de qualidade, é chamada de recompensa.
Essa é uma imagem que ilustra a interação do agente com o ambiente e é mostrada em praticamente qualquer material que você encontre sobre o assunto:

Eu já falei sobre isso aqui no portal e se quiser mais detalhes de uma aplicação de aprendizado por reforço, pode ver aqui.
Em resumo, o agente treina com o objetivo de maximizar o ganho total de recompensa e nesse caminho aprende a realizar alguma tarefa. Esta tarefa se torna assim uma espécie de capacidade que a IA adquire e, como dizem os autores, pode ser vista como uma espécie de inteligência.
É a essa ideia de “inteligência” que nos referimos quando usarmos o termo a partir de agora. Não se atenha muito ao pé da letra, pois inteligência é algo muito difícil de se definir e os autores apenas se referem a esta capacidade ou habilidade adquirida pelo agente.
A hipótese da recompensa
Temos então a hipótese levantada pelos autores:
Hipótese: inteligência, e suas habilidades associadas, pode ser entendida como subserviente à maximização de recompensa por um agente atuando em seu ambiente.
Se verdadeira, essa hipótese sugere que um agente bom em maximizar a recompensa para atingir um determinado objetivo pode desenvolver características associadas à inteligência.
Para argumentar sobre a validade da hipótese os autores apresentam uma série de inteligências complexas que foram adquiridas por agentes e publicadas nos últimos anos. Vejamos alguns detalhes:
Recompensa é suficiente para a conhecimento e aprendizado
Definindo conhecimento como a informação que é interna ao agente, ela pode por exemplo estar associada aos parâmetros internos do agente para selecionar as melhores ações, predizer recompensas futuras ou ainda predizer o comportamento futuro do ambiente. Alguma parte do conhecimento pode ser inata, um conhecimento prévio inserido no agente (falo um pouco disso nesse SPIN de notícias), enquanto outra parte pode ser adquirida durante o treinamento, a interação com o ambiente.
É claro que quanto mais complexo for o ambiente ou o objetivo do agente, mais conhecimento adquirido e inato serão necessários. Por exemplo, para construir um veículo autônomo devemos dar a ele inicialmente a habilidade de localização (GPS), a capacidade de identificar pessoas nas ruas e distingui-las de objetos, reconhecer sinais de trânsito e interpretá-los corretamente. Por outro lado, ele pode aprender quais são as melhores rotas ou evitar ruas que foram danificadas com o tempo.
No exemplo do artigo que cito no SPIN acima, o robô aprendeu a andar melhor e com menos tempo de treinamento devido ao conhecimento prévio de possíveis movimentos, em vez de precisar aprender também os movimentos que poderia fazer.
Recompensa é suficiente para a percepção
Percepção é uma habilidade muito importante da vivência de um ser vivo. Precisamos ver e identificar objetos, distinguir uma pessoa da outra, ouvir sons, sentir cheiros, texturas, calor, umidade, etc. Então, a percepção envolve uma vasta gama de habilidades diferentes e mesmo hoje em dia descobrimos animais com percepções até então inéditas.
Acredito que o aprendizado de percepção em geral é a habilidade mais pesquisada usando inteligência artificial, dentre as que vamos abordar aqui.
Apresentei neste SPIN um exemplo de destreza robótica que faz uso de complexos tipos de percepção.
Recompensa é suficiente para a inteligência social
A inteligência social trata da habilidade dos agentes entenderem e interagirem de modo eficiente com outros agentes. Podemos ter um ambiente em que existem diversos agentes que podem estar competindo, colaborando ou mesmo podem ter objetivos distintos. A maior parte dos trabalhos nessa área envolve uma modelagem usando teoria dos jogos. Geralmente os agentes buscam situações de equilíbrio em que todos se beneficiam.
De acordo com a hipótese da recompensa esse desenvolvimento de inteligência social pode ser obtido pela maximização de recompensa por um agente em um ambiente com outros agentes. O interessante aspecto desse problema é que cada agente pode aprender com o comportamento dos demais e também influenciá-los com suas ações. Um agente que consegue antecipar e influenciar o comportamento dos outros. Assim, se um ambiente necessita de inteligência social, ela pode ser atingida com maximização de recompensa.
Um trabalho incrível de aprendizado por reforço sendo aplicado à inteligência social foi desenvolvido pela OpenAI. Os agentes jogam um jogo de esconde-esconde. Após muito treinamento eles aprendem habilidades incríveis como: cooperação (um agente distrai o perseguidor enquanto outros preparam o ambiente para se esconder) e sacrifício (um se sacrifica para que os demais possam se esconder).
Para mais exemplos veja a coleção de vídeos abaixo (obs: se tiver tempo assista todos os vídeos, são incríveis):
Teremos mais
Bom, esse é o fim da primeira parte sobre esse artigo. Voltarei em breve para falar das outras inteligências (linguagem, generalização e imitação) e para finalizar como isso tudo resulta na inteligência artificial geral.
Você acha que os autores estão precipitados? Ou acha que esse será um artigo histórico marcando o início do caminho da singularidade?
Nos vemos em breve :)




